Somewhere in my mother’s basement, is my prized 1995 tie-dyed DARE tee-shirt, a paradoxical relic of elementary classroom hours spent discussing the dangers of peer-led drug use. Those fears were not unwarranted, the CDC (Center for Disease Control) reports that 136 Americans die daily from opioids and illicitly manufactured fentanyl1, for me - a friend or three. In my experience, most drug prevention programs portray cannabis as the catalyst to the life doomed by addiction.
When recreational cannabis use became legal in Michigan, the culture shift was palpable. In an ironic twist of fate, the taboo habits of those once deemed as social deviants are now capitalized and funding K-12 education2. I am fascinated by this turn of events, and I am curious if there are predictors from more tenured “green” states that reveal unintended ill-consequences.
In my data mining project, I explore the relationship between the presence of cannabis dispensaries and neighborhood crime rates. By replicating the methodology of Brinkman and Mok-Lamme’s 2019 study, “Not in my backyard? Not so fast. The effect of marijuana legalization on neighborhood crime” (NIMBY), I aim to contribute a nuanced perspective on this budding industry and how it shapes public safety and city planning.
My approach involved immersing myself in the wild world of crime and cannabis statistics in Colorado. Using the data sources outlined in NIMBY, I built the variables defined in NIMBY’s linear regression model, described in more detail in the methods section.
In line with the results in NIMBY, my findings indicate that there is no statistically significant relationship between an increased presence of cannabis dispensaries and crime.
- Related Works
A related and noteworthy body of work is the 2021 meta-analysis conducted by D. Mark Anderson and Daniel I. Rees’ paper “The Public Health Effects of Legalizing Marijuana.” The appendix presents an extensive comparison of 70 studies related to the impact of marijuana legalization on public health outcomes by empirical strategy, and study results. This paper served as an excellent resource to understand the myriad of ways in which this topic is being studied, including the study I will replicate. The authors ultimately conclude that while the existing body of research benefits from a wealth of state-level data, the outcomes remain inconclusive. Further research along with careful policy design is needed to mitigate the negative impact of legalization on crime rates and other outcomes.
In contrast, the 2019 paper “Marijuana Dispensaries and Neighborhood Crime and Disorder in Denver, Colorado” by Lorrine A. Hughes, Lonnie M. Schaible, and Katherine Jimmerson offers contradictory findings. Utilizing a Bayesian Poisson regression model, the authors discovered a statistically significant correlation between the presence of dispensaries and increased rates of neighborhood crime—except for murder and auto theft. This study highlights the complexities of the issue and the necessity for a more nuanced understanding of the interplay between cannabis dispensaries and crime rates.
- Methods
While all of the data referenced in NIMBY is publicly available, I found it necessary to deviate from the original’s papers methodology due to data quality issues and time constraints.
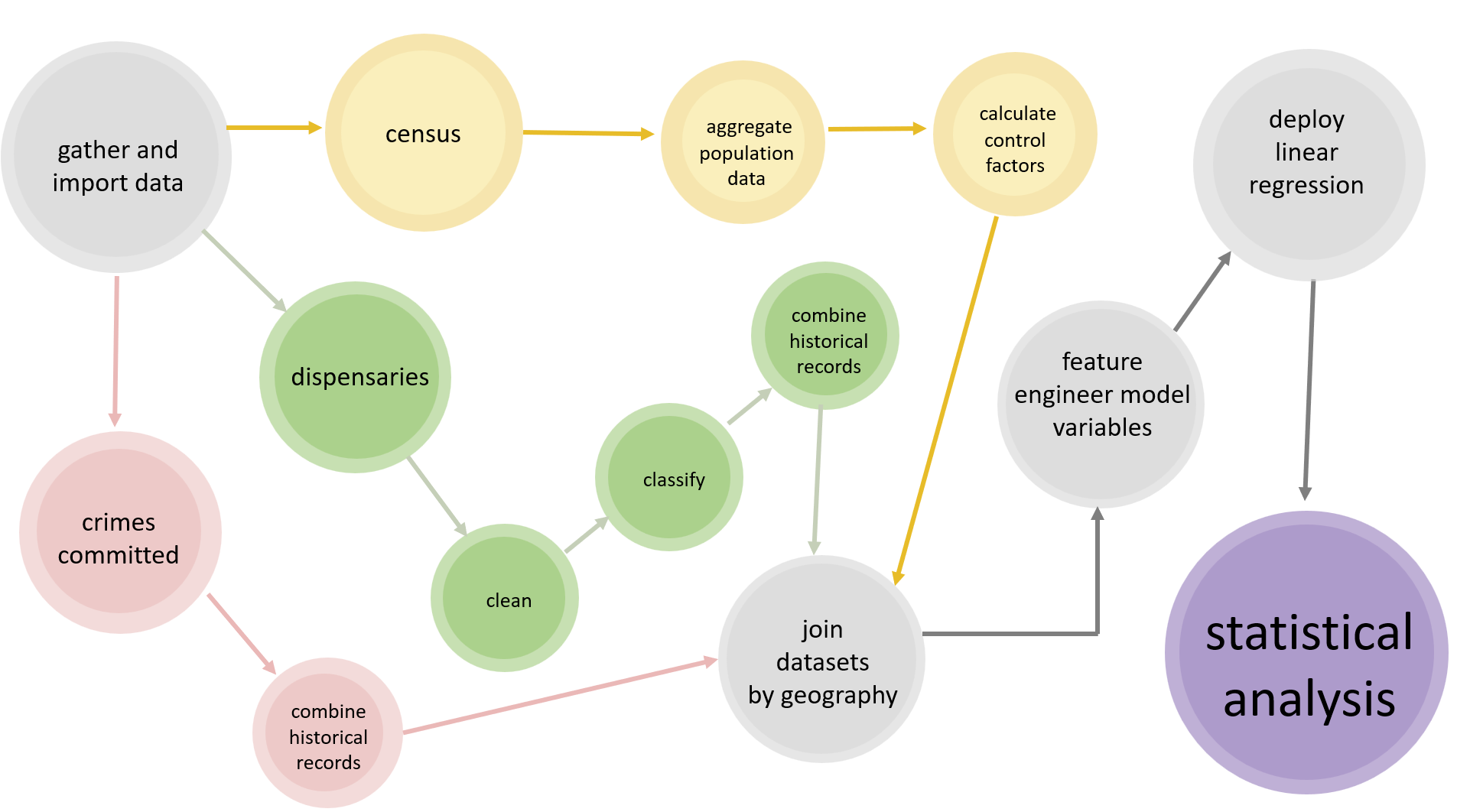
My diagram below illustrates the utilization of R code to construct a data pipeline for the linear model and its associated variables.
In the interest of interpretability, I divided my work into four distinct segments, each highlighted in the navigation bar of this site. I hope this structured breakdown allows readers to navigate through my process efficiently, providing transparent insight into my methods employed and limitations faced throughout this project.
In summation, the data mining pipeline consisted of several stages, each color coded above.
Dispensary license records were cleaned and pre-processed, removing irrelevant columns, standardizing the format, and aggregating the data by county and year. | code
Leveraging the power of the TidyCensus package, I extracted population data for the target variables from the American Community Survey (ACS) census database. | code
I wove the datasets together using county-level identifiers (GEOID), allowing for the computation of per capita values for dispensaries and crime rates and year-over-year fluctuations. | code
Finally, I introduced the new variables into a linear regression model. | code
The goal is to estimate the causal effect of changes in dispensary density on changes in crime rates, while accounting for potential biases and confounding factors using the linear regression model above.
Variable
Defined
Δcrime j,t
year-over-year changes in crime rates the jth geography in month t
Δdisp j,t
year-over-year changes in dispensary rates
j
neighborhood
t
time
𝛽0
(intercept) baseline level of year-over-year changes in crime rates
𝛽1
(coefficient) expected change in year-over-year crime rates associated with a one-unit increase
𝛽2
vector of estimated coefficients on the control variables (demographic characteristics, economic conditions)
X
a vector of control variables (demographic characteristics, economic conditions)
Δ𝛿t
time fixed effects
⋲ j,t
error term
- Results and Discussion
To gauge the differences between my work and NIMBY, I recreated a couple of the visual aids.
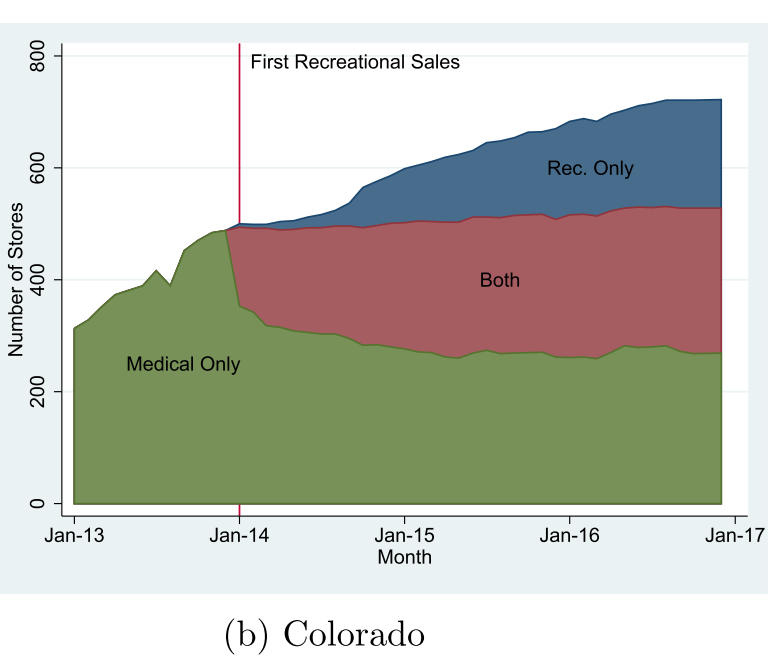
Comparing Dispensary Counts
Figure 1. From NIMBY:
how to read: “The panels of this figure show the total number of store fronts (calculated using data from Colorado Department of Revenue) cross tabbed by stores that sell only medical marijuana (green), both medical and recreational marijuana (red), and only recreational marijuana (blue). The vertical red line shows the first date (January 1, 2014) when recreational sales were legal.” (Brinkman Pg. 5)
interpretation: Once recreational cannabis was legalized in Colorado, we see a many dispensaries begin selling both recreational and medical products. In 2015 Retail only store begin their growth trajectory while medical and both types remain relatively flat.
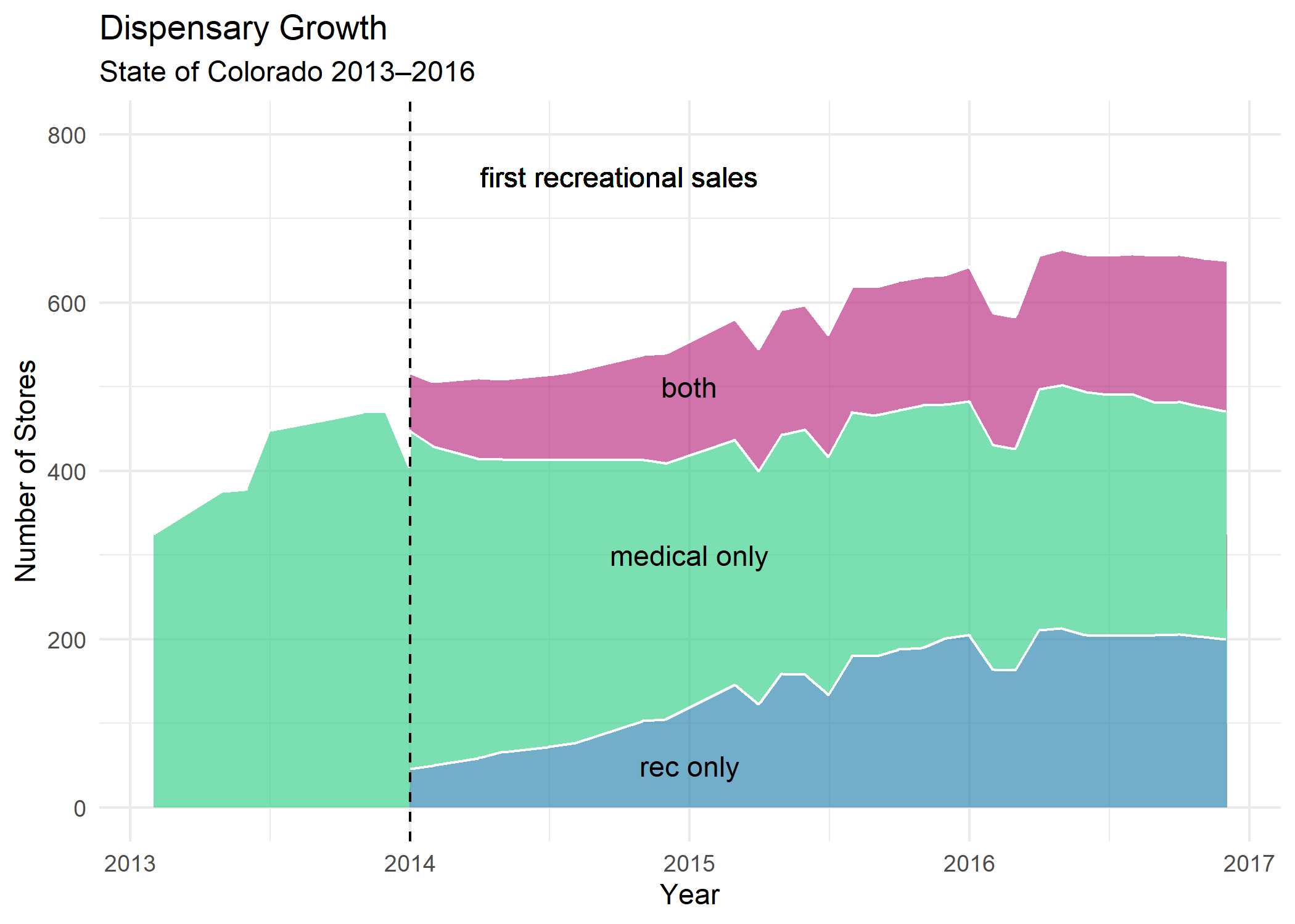
Replicated Area Graph
comparison: Although I applied a different approach, my total counts are similar to the original study. The graph tells a similar story as the one above, outside of the the missing data sets in 2016 .
Comparing Control Variables
Table 1. From NIMBY:
how to read: Panel B, shows the county quartiles (lowest to highest) by the four variables. The figures represent the three-year average of year-over-year growth in dispensary businesses. (Brinkman Pg. 6)
interpretation: the average county in Colorado saw a 11.9% increase in the number of dispensaries between 2014-2017. Counties that fall within the 4th quartile (highest) for poverty rates saw the largest increase (22.1%) average growth in the number of dispensaries, followed by the 4th quartile for Hispanic populations, and the 1st quartile (lowest) employed populations.
Replicated Table
comparison: now let’s look at my results, my calculations led me to a 11.5% three-year average growth in dispensaries, which is very close to NIMBY’s result. However, when I compare the individual demographics there is a lot of variance between the two results. The lowest quartile for employed populations revealed the most growth in dispensaries (+50.8%), followed by the 2nd quartile for black populations (27.0%).
The gaps between my employment quartiles and NIMBY’s are too wide to ignore. With more time, I’d explore the difference in methodologies and identify the contributing factors.
- Conclusions
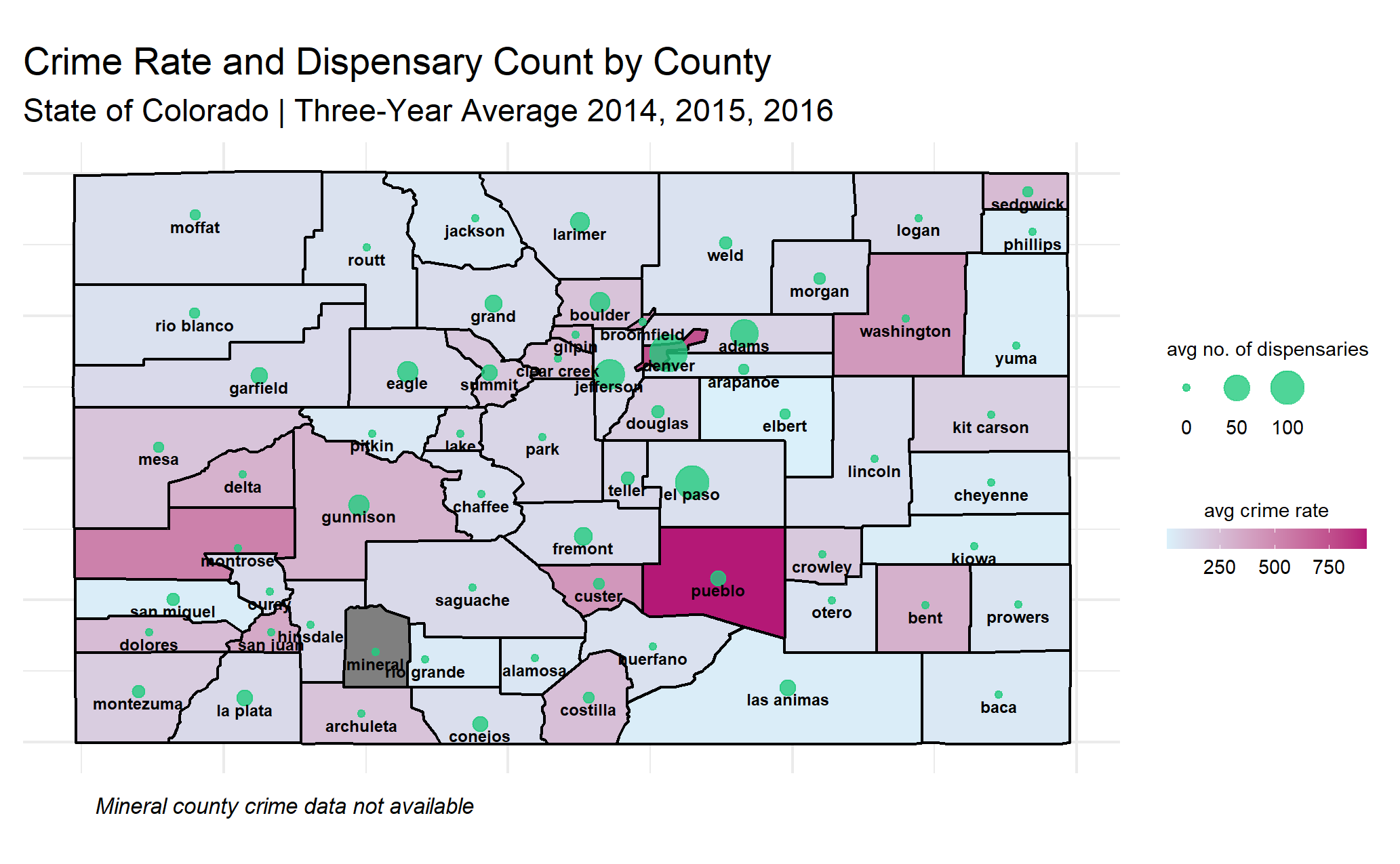
Comparing the Dependent and Independent Variables:
how to read:the three-year average of crimes per 10,000 residents are plotted by Colorado county, overlaid by the three year average count of dispensaries with in the county.
interpretation: Denver is clearly where we see the larger crime rates, and more dispensaries. NIMBY refers to Denver as the “mecca of recreational cannabis.” El Paso is an interesting county with a relativity high dispensary density and low crime rate, as well as pueblo county where the inverse is true
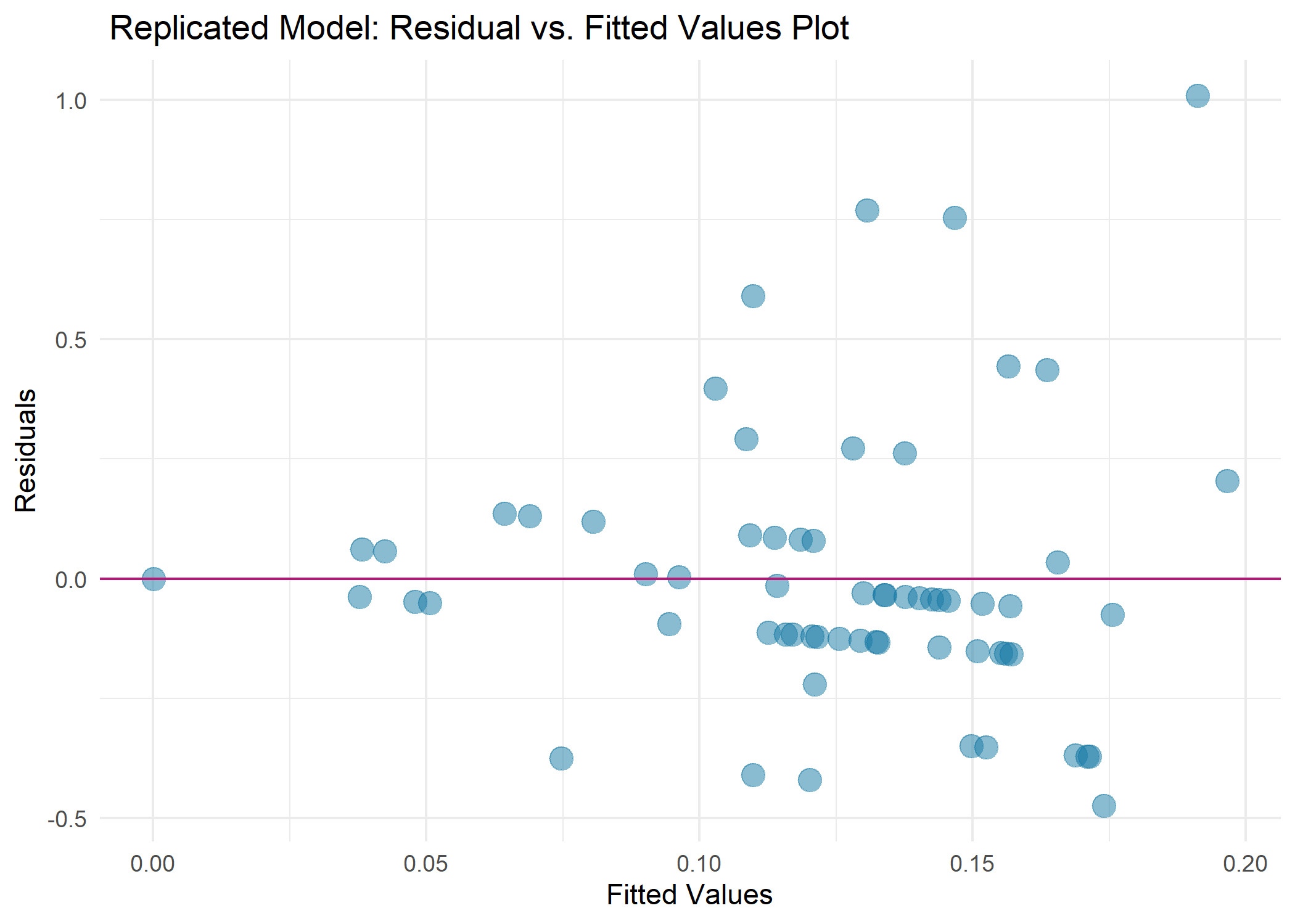
Evaluating the Model
How to read:the x axis is the predicted value of crime rate change, and the y is the difference between the actual values against the predicted
interpretation:This plot helps determine the accuracy of my model in determining the relationship between county crime rates growth and county dispensary density growth, while controlling for poverty rate, racial demographics, and employment rate. The x-axis represents the crime rate predictions made by the model, while the y-axis represents the difference between these predictions and the actual observed crime rates.
The unequal distribution of plots around the horizontal line (y=0), indicates my model not an ideal fit for the data.
Call:
lm(formula = linear_variables$crime_yoy_avg ~ linear_variables$dsp_yoy_avg +
linear_variables$pct_poverty_rate + linear_variables$pct_black +
linear_variables$pct_hispanic + linear_variables$employeed_pop,
data = linear_variables)
Residuals:
Min 1Q Median 3Q Max
-0.47400 -0.13238 -0.04318 0.08269 1.00885
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.627e-02 1.145e-01 0.753 0.454
linear_variables$dsp_yoy_avg -6.323e-02 1.543e-01 -0.410 0.683
linear_variables$pct_poverty_rate 6.074e-01 9.582e-01 0.634 0.529
linear_variables$pct_black -2.071e-01 1.514e+00 -0.137 0.892
linear_variables$pct_hispanic -1.692e-01 3.680e-01 -0.460 0.647
linear_variables$employeed_pop -2.045e-07 4.720e-07 -0.433 0.666
Residual standard error: 0.2976 on 58 degrees of freedom
Multiple R-squared: 0.01903, Adjusted R-squared: -0.06554
F-statistic: 0.225 on 5 and 58 DF, p-value: 0.9502
Reviewing the summary output, there are several indicators that my model is a poor fit for the data:
the negative adjust r-square
low multiple R square, reveals that dispensary density only explains about 1.9% of the variation in crime rates
the residuals skew left
Additionally, the high p-value (0.95) indicates that we can not reject the null hypothesis that dispensary presences has no effect on crime rates.
Comparison:
This model is part of NIMBY’s baseline estimation strategy. Their next model iteration adds in another explanatory variable “miles from the border.” It is from this final set of variables they draw their conclusions. Additionally, while most of the insights in NIMBY look at the census tract level, the authors discuss the county effects:
“The OLS estimates show no significant correlation between changes in dispensary density and changes in crime at the county level. The IV estimates are consistent with the tract-level results, showing some evidence of reduced crime in counties that received more dispensaries.
The results, however, are weaker both economically and statistically, which is to be expected given that we have shown that the effects tend to be contained at the neighborhood level where the dispensaries are located.”(Brinkman and Mok-Lamme 2019)
Final Thoughts:
The third law of Tom Khabaza’s Nine Laws of Data Mining states that “Data preparation is more than half of every data mining process.” Throughout this project, I embraced this maxim as I worked my way through various data quality issues. Predicting the relationship between recreational cannabis legalization and crime rates is no straightforward task. Even with careful data construction , an accurate predictive model takes trial and error, domain knowledge, and a stamina for problem solving. After this experience, I am more inclined to trust the results of meta-analyses of existing studies than one sole research study.
In order to fully address the concerns surrounding the longterm implications of legal recreational cannabis use, we need to look at the issue from multiple angles. As for Michigan, if I were to attempt a similar study, I would take a completely different approach. Crime rates are influenced by so many factors, I would spend my time analyzing the dynamics in state revenue and how those funds are being spent and how the multiplicities benefited.
Brinkman, J., & Mok-Lamme, D. (2019). Not in my backyard? Not so fast. The effect of marijuana legalization on neighborhood crime. Regional Science and Urban Economics, 78. https://doi-org.ezproxy.gvsu.edu/10.1016/j.regsciurbeco.2019.103460
Anderson, D. M., & Rees, D. I. (2023). The Public Health Effects of Legalizing Marijuana. Journal of Economic Literature, 61(1), 86–143. https://doi-org.ezproxy.gvsu.edu/10.1257/jel.20211635
Hughes, Lorine A., Lonnie M. Schaible, and Katherine Jimmerson. “Marijuana Dispensaries and Neighborhood Crime and Disorder in Denver, Colorado.” Justice Quarterly, vol. 37, no. 3, 2020, pp. 461-485, doi: 10.1080/07418825.2019.1567807.
References
Becker, Original S code by Richard A., Allan R. Wilks. R version by Ray Brownrigg. Enhancements by Thomas P Minka, and Alex Deckmyn. 2022. “Maps: Draw Geographical Maps.”https://CRAN.R-project.org/package=maps.
Brinkman, Jeffrey, and David Mok-Lamme. 2019. “Not in My Backyard? Not so Fast. The Effect of Marijuana Legalization on Neighborhood Crime.”Regional Science and Urban Economics 78 (September): 103460. https://doi.org/10.1016/j.regsciurbeco.2019.103460.
Cambon, Jesse, Diego Hernangómez, Christopher Belanger, and Daniel Possenriede. 2021. “Tidygeocoder: An r Package for Geocoding” 6: 3544. https://doi.org/10.21105/joss.03544.
Hester, Jim, Hadley Wickham, and Gábor Csárdi. 2021. “Fs: Cross-Platform File System Operations Based on ’Libuv’.”https://CRAN.R-project.org/package=fs.
Walker, Kyle, and Matt Herman. 2023. “Tidycensus: Load US Census Boundary and Attribute Data as ’Tidyverse’ and ’Sf’-Ready Data Frames.”https://CRAN.R-project.org/package=tidycensus.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019. “Welcome to the Tidyverse” 4: 1686. https://doi.org/10.21105/joss.01686.
Drug Abuse Statistics. “Drug Overdose Deaths.” Drug Abuse Statistics, 2022, https://drugabusestatistics.org/drug-overdose-deaths, Accessed 12 Apr. 2023.↩︎
Michigan Department of Treasury. “Adult-Use Marijuana Payments Being Distributed to Michigan Municipalities and Counties.” Michigan.gov, 28 Feb. 2023, https://www.michigan.gov/treasury/news/2023/02/28/adult-use-marijuana-payments-being–distributed-to-michigan-municipalities-and-counties, , Accessed 12 Apr. 2023.↩︎


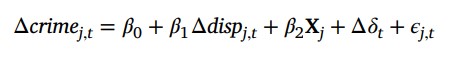
.jpg)